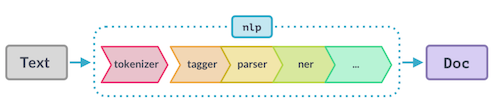
nlp : contains the processing pipeline; includes language-specific rules for tokenization etc.
doc : access information about the text in a structured way, and no information is lost.
token : tokens in a document – for example, a word or a punctuation character.
span : a slice of the document consisting of one or more tokens
lexical attributes : token.i, token.text, token.is_alpha, token.is_punct, token.like_num… They refer to the entry in the vocabulary and don’t depend on the token’s context.
# 导入对应语言类 Note: Some language tokenizers require external dependencies. from spacy.lang.zh import Chinese # https://spacy.io/usage/models 查看lang后面对应的字符
# 创建nlp实例 nlp = Chinese()
# 使用nlp对象处理一段文本并生成doc实例 # When you call nlp on a string, spaCy first tokenizes the text and creates a document object. doc = nlp("这是一个句子。") # 底层调用 __call__方法
for token in doc: # 遍历doc实例中的token print(token.text) ''' 这是 一个 句子 。 '''
# 使用索引获得某一个token specific_token = doc[1]
# 使用切片获得doc片段 span = doc[1:3]
# token的一些属性 doc = nlp("我花了20¥买了一个汉堡包。") print("Index: ", [token.i for token in doc]) print("Text: ", [token.text for token in doc]) print("is_alpha:", [token.is_alpha for token in doc]) print("is_punct:", [token.is_punct for token in doc]) print("like_num:", [token.like_num for token in doc]) ''' Index: [0, 1, 2, 3, 4, 5, 6, 7, 8] Text: ['我花', '了', '20', '¥', '买', '了', '一个', '汉堡包', '。'] is_alpha: [True, True, False, False, True, True, True, True, False] is_punct: [False, False, False, False, False, False, False, False, True] like_num: [False, False, True, False, False, False, False, False, False] '''
统计模型
来源: Models are trained on large datasets of labeled example texts. 作用: 词性标注 (Part-of-speech tags), 依存关系解析 (Syntactic dependencies), 命名实体识别 (Named entities) 优化: Can be updated with more examples to fine-tune predictions
import spacy nlp = spacy.load("en_core_web_md") # load a model package by name and returns an nlp object.
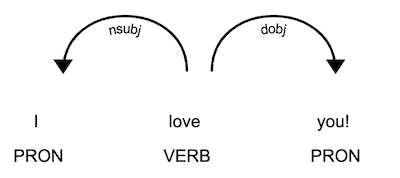
# Process a text doc = nlp("I love you!")
# Iterate over the tokens for token in doc: # Print the text and the predicted part-of-speech tag print(token.text, token.pos_) ''' I PRON love VERB you PRON ! PUNCT '''
for token in doc: print(token.text, token.pos_, token.dep_, token.head.text) ''' I PRON nsubj love love VERB ROOT love you PRON dobj love ! PUNCT punct love '''
# Process a text doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
# Iterate over the predicted entities for ent in doc.ents: # Print the entity text and its label print(ent.text, ent.label_)
# Process a text doc = nlp("Microsoft Corporation is an American multinational technology company with headquarters in Redmond, Washington.")
# Iterate over the predicted entities for ent in doc.ents: # Print the entity text and its label print(ent.text, ent.label_) ''' Microsoft Corporation ORG American NORP Redmond GPE Washington GPE '''
# Get quick definitions of the most common tags and labels. spacy.explain('NORP') 'Nationalities or religious or political groups'
# Process some text doc = nlp("Upcoming iPhone X release date leaked")
# Call the matcher on the doc matches = matcher(doc)
# Iterate over the matches for match_id, start, end in matches: # Get the matched span matched_span = doc[start:end] print(matched_span.text) print(nlp.vocab.strings[match_id]) # 通过match_id 获取当初加入pattern的名称)
'iPhone X' 'IPHONE_PATTERN'
''' {"OP": "!"} Negation: match 0 times {"OP": "?"} Optional: match 0 or 1 times {"OP": "+"} Match 1 or more times {"OP": "*"} Match 0 or more times '''
pattern = nlp("Golden Retriever") # 和Matcher不同的地方 matcher.add("DOG", None, pattern) doc = nlp("I have a Golden Retriever")
# 遍历匹配结果 for match_id, start, end in matcher(doc): # 获取匹配到的span span = doc[start:end] print("Matched span:", span.text)
# 多个pattern如何进行add # 下面的代码比这样的表达方式更快: [nlp(country) for country in COUNTRIES] patterns = list(nlp.pipe(COUNTRIES)) matcher.add("COUNTRY", None, *patterns)