Scrapy学习
Scrapy 架构
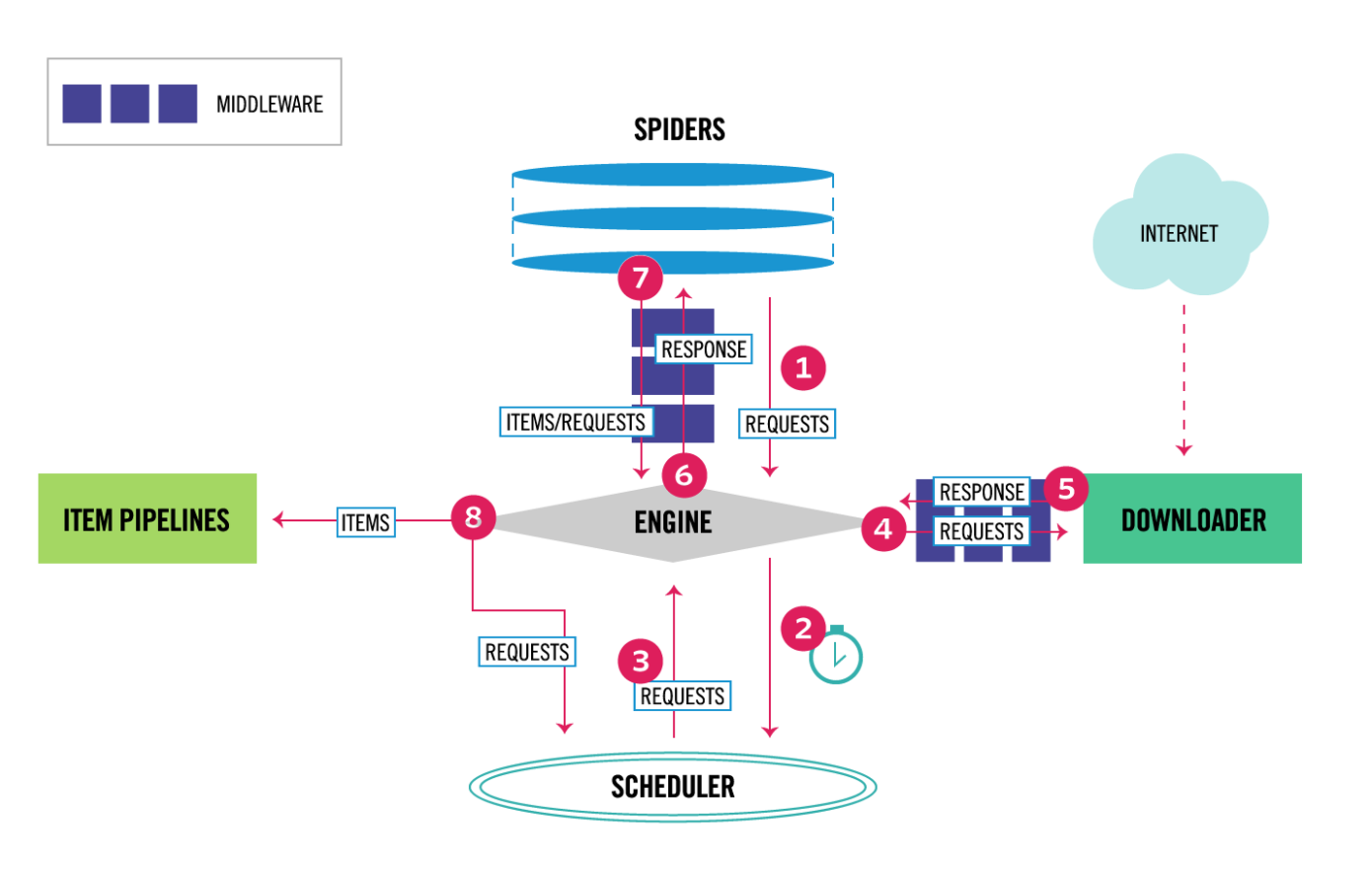
- The Engine gets the initial Requests to crawl from the Spider.(获取要爬的url)
- The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.(调度request到调度器中,形成一些列的url调度队列)
- The Scheduler returns the next Requests to the Engine.(调度器调度完成,发送第一个request给引擎)
- The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (see process_request()). (引擎发送第一个request给下载器)
- Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (see process_response()).(下载器得到该request的response,返回给引擎)
- The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (see process_spider_input()).(引擎将response发给spider进行解析)
- The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (see process_spider_output()).(spider解析好需要的数据:包括:提取需要的内容+提取新的url请求,将处理好的数据发给引擎)
- The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.(一方面引擎将得到的内容发给item,将得到的url请求发给调度器)
- The process repeats (from step 1) until there are no more requests from the Scheduler.
摘自:https://docs.scrapy.org/en/latest/topics/architecture.html
Scrapy 使用
第一步: 创建爬虫项目;
$scrapy startproject project_name
第二步: 设置settings
settings关闭robots =》 POBOTSOXT_OBEY = True
…
第三步: 定义item信息
1 | |
第四步:编写代码逻辑
1 | |
第五步:调试 输出
$ scrapy shell URL
response.xpath(xxx).getall()
$ scrapy crawl quotes -o xx.json
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!