推荐系统总览
效用矩阵 (utility matrix)
一般的推荐系统中有两类元素,一类是user,一类是item(例如电影、音乐…),可以用一个矩阵表示这些数据
每一行表示每一个user,每一列表示一个item, M[i][j]表示第i个用户对第j项的评分。
一般效用矩阵都是稀疏的,需要做的就是填充这些缺失值
- Gathering known ratings for matrix
- Extrapolate unknown ratings from the known ones
- Evaluating extrapolation methods
长尾效应 (The Long tail)
物理世界和在线世界的差别称为长尾现象,长尾现象要求互联网必须对每个用户进行推荐。
- 实际的物理实体店中受限于空间,只能推荐畅销项目。
- 互联网推荐系统不受空间限制,可以推荐所有项目。
关于在线世界与物理世界差异的例子:
What percentage of the top 10,000 titles in any online media store (Netflix, iTunes, Amazon, or any other) will rent or sell at least once a month?
Most people guess 20 percent.(80-20 rule, also known as Pareto’s principle (1896))
The right answer: 99 percent.(Demand for nearly every one of those top 10,000 titles.)
推荐算法分类
基于内容(Content based)
思想:关注item的属性,计算各个item之间的相似度来进行推荐。 Recommend items to customer x that are similar to previous items rated highly by x.
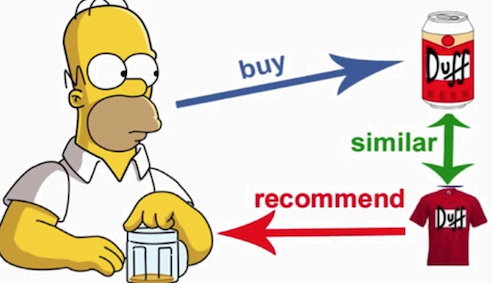
工作原理
基于内容的推荐系统是建立在用户给出的数据之上的,用户给出的数据要么是对物品的直接评分或者是点击或者浏览物品,通过这些数据可以建立出基于这个用户的基本信息(user profile),后续对该用户物品推荐是基于其user profile,user profile越完善,推荐系统的效果越好。
工作流程
- Construct item profiles (构建描述item的向量)
- 特征可以是明确的属性值,也可以是从文档中提取出来的特征
- Construct user profiles (构建描述user喜好的向量)
- 将user的偏好也表示成同一空间下的向量
- Recommend items to users based on content
优劣
优点:
- 不需要其他user的数据
- 可以根据user的独特喜好来推荐item,也就是说可以推荐一些小众的item
- 推荐的原因可以很容易被解释
缺点: - 内容的特征提取的问题,如何才能提取出最有用的特征(requires a lot of domain knowledge.)
- 只能推荐与用户历史数据中相似的item(model has limited ability to expand on the users’ existing interests)
- 无法利用其他用户的数据
协同过滤(Collaborative filtering)
思想:关注item与user之间的关系,先识别相似用户,然后基于相似用户进行相似项目进行推荐。 Suggestions made to a user utilizing information across the entire user base
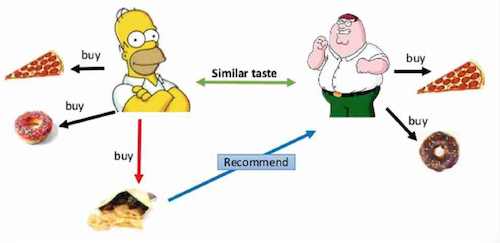
工作原理
基于协同过滤的推荐系统是建立在许多用户的数据之上的,通过分析这些用户之间的相似度,发掘相似的用户,(假设用户A和B相似),推荐A一些B买过的东西。其主要精髓在于:物以类聚(item-based),人以群分(user-based)。
It’s based on the idea that people who agree in their evaluations of certain items in the past are likely to agree again in the future.
关于一点思考:Users only see what they are expected to like.
协同过滤的两类算法
Memory-based approach
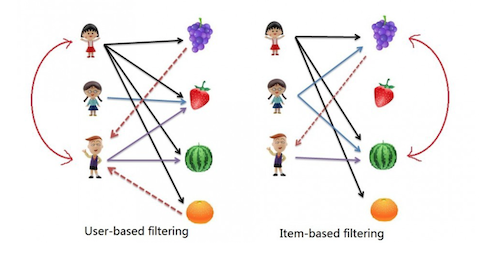
User-based CF (k-nearest neighbor collaborative filtering)
- 思想: 为用户A找到相似用户,然后基于相似用户进行相似项目推荐
- 步骤:
- 根据与A的相似度来为A的相似用户分配权重
- 选择topk相似用户
- 基于topk相似用户对于item的评分去预测A对item的评分
- 例子: 假设A有3个相似用户,B(sim=0.8, rating(h)=5),C(sim=0.3,rating(h)=4),D(sim=0.5,rating(h)=3) 预测A对于h的评分
- r_a(h) = 0.8x5+0.3x4+0.5x3 / (0.8+0.3+0.5) = 4.2
Item-based CF
- 思想: 为物品x找相似物品,然后基于用户之前喜欢/买过的物品为其推荐最相似的物品
- 例子: 为电影进行评分时, similar items will be rated similarly by the same user
Model-based approaches
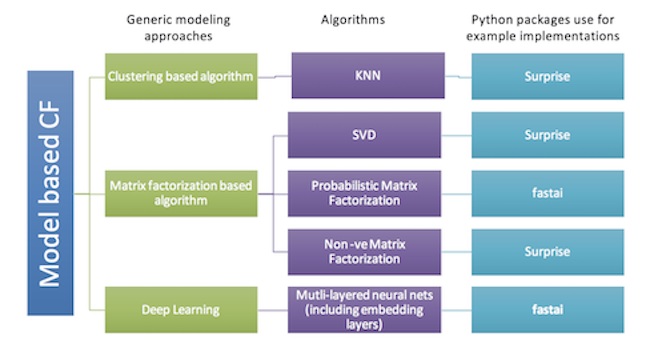
矩阵分解
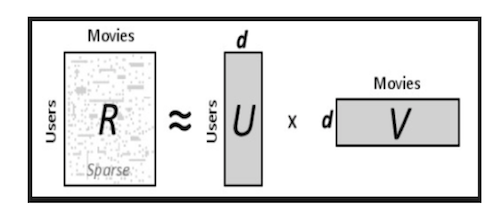
CF优劣
优点:
- 利用了别的user的数据
- 不需要特征选择(不需要domain knowledge)
缺点:
- 需要足够的数据支持
- 稀疏,构建出的utility matrix稀疏且庞大
- 无法推荐从未被评级的item
- 不能根据某个用户的特有品位进行推荐
混合方法(Hybrid)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!