知识图谱识别
前情提要
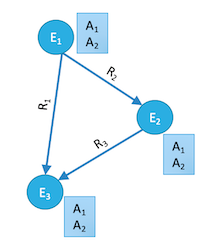
在知识图谱中,主要需要解决的有三个问题: (节点,属性,关系)
- Who are the entities (nodes) in the graph?
- What are their attributes and types (labels)?
- How are they related (edges)?
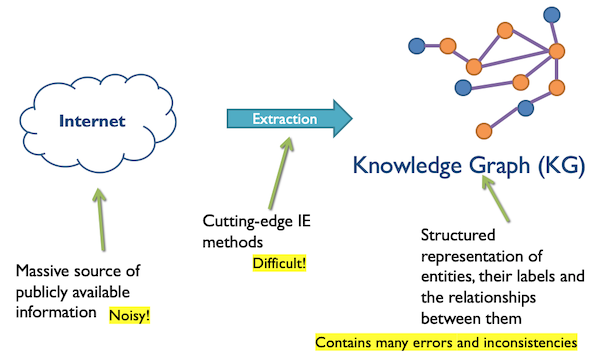
知识图谱的构建主要就是通过IE将互联网上各式各样的资源进行提取,整合得到结构化的数据(说起来容易,做起来难!)
提取到的知识可能存在的一些问题:
- ambiguous (一般我们说ambiguous 指的是多个entity指向一个名字, variant指的是一个entity有多个名字)
- Beetles, beetles, Beatles 这三个name可能都是指向一个实体甲壳虫,但是名字不同
- citizenOf, livedIn, bornIn 这三个property可能都是指向一个实体,表达的意思为该实体住在某一个地方
- incomplete
- missing relationship; missing labels; missing entities
- inconsistent
- exclusive labels (alive, dead), 提取到的知识表明一个人既已经去世又还在人世
- domain-range constraints,提取到一个relationship例如人的年龄为一朵花的名字(age属性一般为int)
- 一个人的配偶有多个存在(common sense: 一般认为配偶为一对)
例子: NELL在知识提取中存在的问题:
NELL: Never-Ending Language Learner CMU研究的一个人工智能语言学习程序,从Web文本中获取知识,并将其添加到内部知识库内 ,使用机器学习算法学习新入库的知识,巩固对知识的理解。
特点: Large-scale IE project; Lifelong learning: aims to “read the web”; Ontology of known labels and relations; Knowledge base contains millions of facts
存在问题:
- Entity co-reference errors, 例如对于Kyrgyzstan(吉尔吉斯斯坦,中亚的一个国家)这样一个实体,他具有许多的variants(Kyrgystan, Kyrgistan, Kyrghyzstan, Kyrgzstan, Kyrgyz Republic), NELL不能很好将这些variant完全映射到同一个实体上。
- Missing and spurious labels, 例如Kyrgyzstan被标注为鸟或者国家
- Missing and spurious relations, 例如Kyrgyzstan的位置,通过IE可能得到不同的地区归属。
- Violations of ontological knowledge
由于知识提取过程中的诸多问题,想要很好的解决这些问题需要jointly considering multiple extractions.
图谱构建方法:
- Clean and complete extraction graph
- Incorporate ontological constraints and relational patterns
- Discover statistical relationships within knowledge graph
PSL (Probabilistic soft logic) 概率软逻辑
It’s not a black-and-white issue.
从一个例子说起, 美国选民派别分类 (Voter Party Classification)
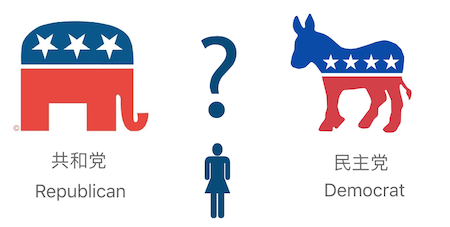
各个角度的信息来分析一名美国选民的政治态度:
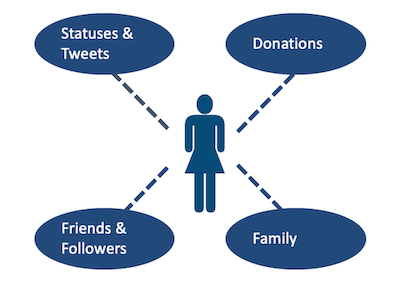
IDEA: Collective Classification
假设分析A的政治态度,可以通过其配偶的政治态度,其tweet粉丝的观点,个人的行为来进行分析,通过制定一些规则来确定这个人是支持共和党还是民主党。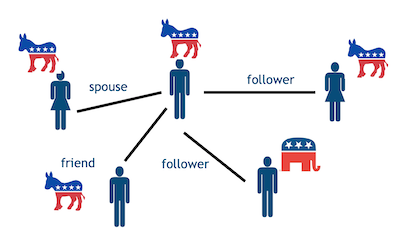
1 | |
为什么需要PSL
通过上面的例子,可以发现,通过制定一些比较好的规则,可以为提取的信息进行一些比较高质量的标注。
存在问题:
规则的制定依赖于提取到的信息,如果提取到的知识存在问题,那么一定是garbage in - garbage out.
例子:
Lbl(Socrates, Man) & Sub(Man, Mortal) -> Lbl(Socrates, Mortal)
假如提取到的知识没有正确的将Socrates标注为男性,那么永远也得不到Lbl(Socrates, Mortal)这样的知识。解决措施: probabilistic models => P(new facts|extraction infos)
P(Lbl(Socrates, Mortal)|Lbl(Socrates,Man)=0.9)多条规则之间可能产生冲突
例子:
B的正确性无法确定:
A -> B 符合
C -> B 不符合
D -> B 符合解决措施: Soft Logic
A -> B 符合 0.7
C -> B 不符合 0.2
D -> B 符合 0.9
Soft Probability
1 | |
PSL model
- PSL finds optimal assignment for all unknowns
- Optimal = minimizes the soft-logic penalty
- Fast, joint convex optimization using ADMM
- Supports learning rule weights and latent variables
图谱模型的建立
步骤:
Define joint probability distribution on knowledge graphs
Each candidate fact in the knowledge graph is a variable
Statistical signals, ontological knowledge and rules parameterize the dependencies between variables
Find most likely knowledge graph by optimization/sampling
Knowledge Graph Identification (KGI)
Knowledge Graph Identification (KGI): 解决图谱中存在的一系列问题的方案
- Performs graph identification:
- entity resolution
- collective classification
- link prediction
- Enforces ontological constraints
- Incorporates multiple uncertain sources
P(Who, What, How | Extractions)
图谱中probability的获得
Statistical signals from text extractors and classifiers
ex:
P(R(John,Spouse,Yoko))=0.75; P(R(John,Spouse,Cynthia))=0.25
LevenshteinSimilarity(Beatles, Beetles) = 0.9
Ontological knowledge about domain
ex:
Functional(Spouse) & R(A,Spouse,B) -> !R(A,Spouse,C)
Range(Spouse, Person) & R(A,Spouse,B) -> Type(B, Person)
Rules and patterns mined from data
ex:
R(A, Spouse, B) & R(A, Lives, L) -> R(B, Lives, L)
R(A, Spouse, B) & R(A, Child, C) -> R(B, Child, C)
定义一个graphical models
有许多种方式去定一个图模型,这里使用PSL(使用规则)
PSL infers a “truth value” for each fact via optimization
Rules for KG Model
1 | |
Rules to Distributions
Rules are grounded by substituting literals into formulas
Ground rules provide a joint probability distribution over knowledge graph facts, conditioned on the extractions
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!