数据挖掘, MapReduce 介绍
Introduction
Terms
Data mining: Discover patterns and models that are:
- Valid: hold on new data with some certainty
- Useful: should be possible to act on the item
- Unexpected: non-obvious to the system
- Understandable: humans should be able to interpret the pattern
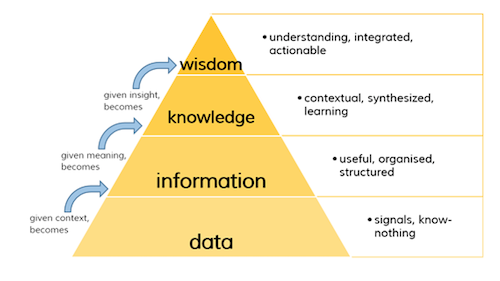
DIKW Pyramid: Data, Information, Knowledge and wisdom
Data mining task:
- Descriptive Models: Find human-interpretable patterns that describe the data
- Predictive Models: Use some variables to predict unknown or future values of other variables
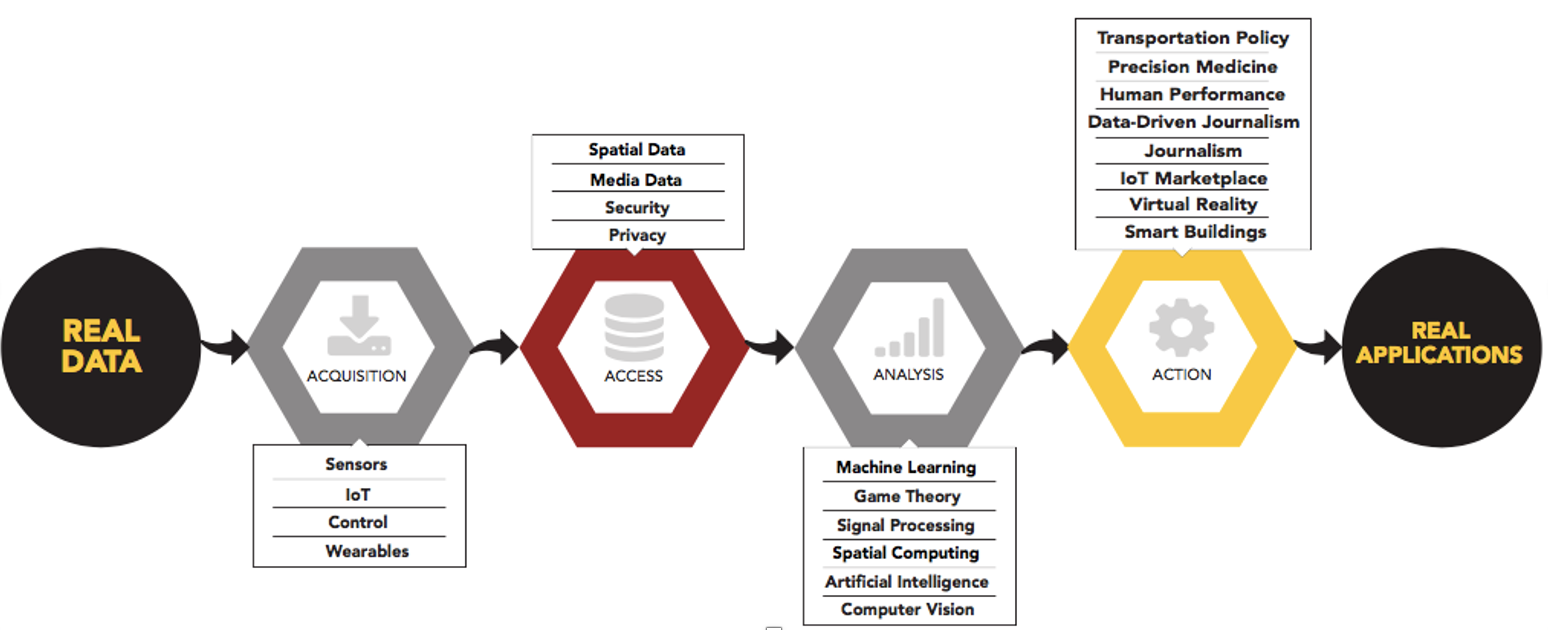
Data science pipeline
Bonferroni’s principle:(roughly) if you look in more places for interesting patterns than your amount of data will support, you are bound to find crap.(数据支撑的前提是数据)
Descriptive Models
Often, especially for ML-type algorithms, the result is a model = a simple representation of the data, typically used for prediction.
example: PageRank : representing the “importance” of the page.
Predictive Models
In many applications, all we want is an algorithm that will say “yes” or “no”
example: spam email detection
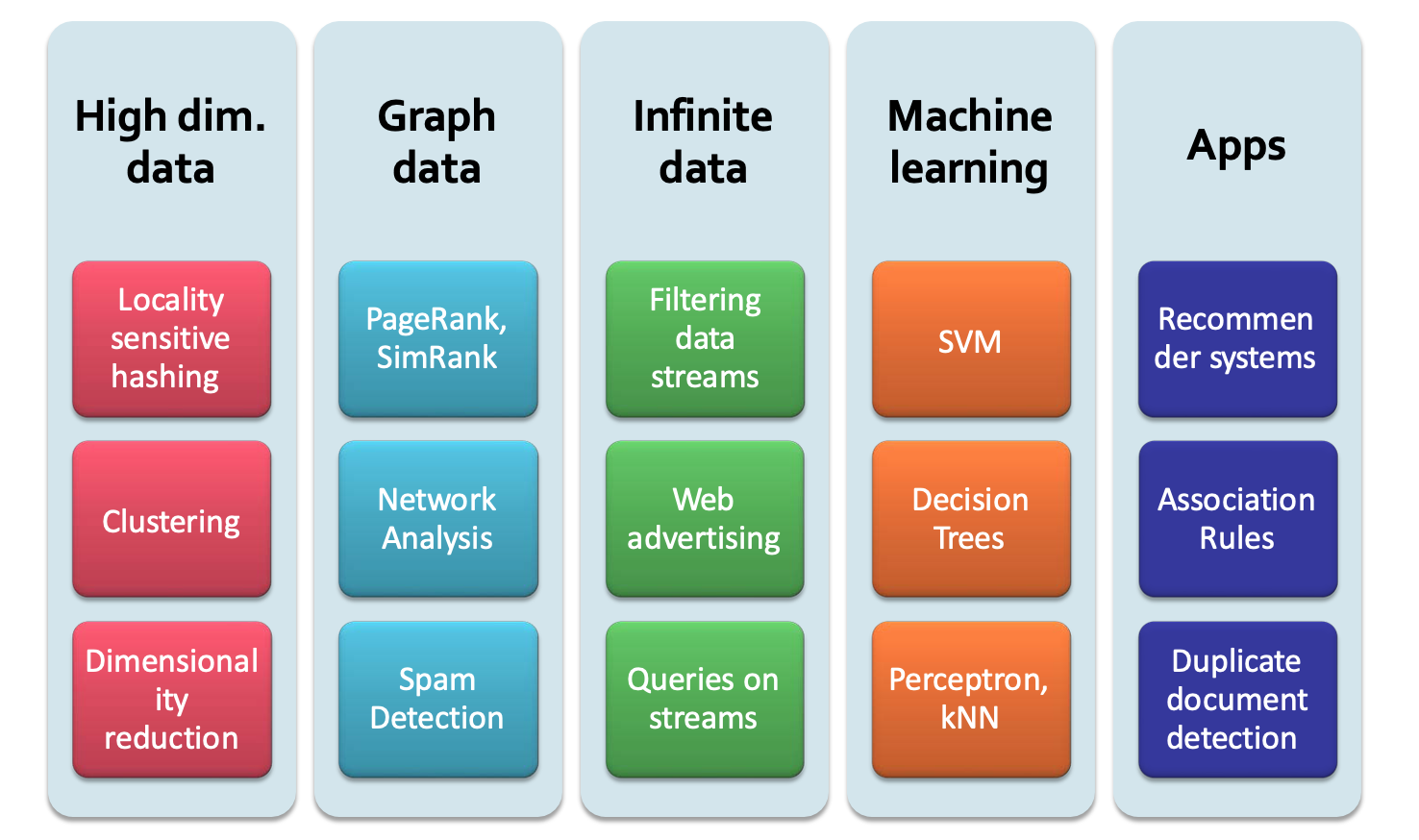
Thing will be convered
Data: high dimensional|graph|infinite/never-ending | labeled
Model: MapReduce |Streams and online algorithms |Single machine in-memory
Real-world problems: Recommender systems| Market Basket Analysis| Spam detection| Duplicate document detection
Theory:
- Linear algebra (SVD, Rec. Sys., Communities)
- Optimization (stochastic gradient descent)
- Dynamic programming (frequent itemsets)
- Hashing (LSH, Bloom filters)
Bonferroni’s Principle
an informal presentation of a statistical theorem:
- that states if your method of finding significant items returns significantly more items that you would expect in the actual population,
- you can assume most of the items you find with it are bogus.
简单的说就是FP过多,误诊率太高。
example:
- Rhine’s Paradox(莱茵悖论), 猜卡片红蓝
- Total Information Awareness (TIA),根据信息预测犯罪, 这个挺有意思。
TIA:
问题定义: “evil-doers” periodically gather at a hotel to plot their evil.
假设: One billion people might be evil-doers; Everyone goes to a hotel one day in 100; A hotel holds 100 people; Examine hotel records for 1000 days;100,000 hotels
策略: look for people who, on two different days, were both at the same hotel.
真实情况: no evil-doers or few evil-doers(let’s say 10), everyone behaves randomly
根据假设得到的结果:
Probability that given persons p and q will be at the same hotel on given day d :
1/100 x 1/100 x 1/100,000 = 10^-9
Probability that p and q will be at the same hotel on given days d1 and d2:
10^-9 * 10^-9 = 10^-18
Pairs of days:
1000 x 999/2 = 5x10^5(roughly)
Probability that p and q will be at the same hotel on some two days:
10^-18 x 5x10^5 = = 5 x 10^-13
Pairs of people:
10^9 x 10^9 /2 = 5 x 10^17 (roughly)
Expected number of “suspicious” pairs of people(根据策略得到的可疑犯罪):
5 x 10^-13 x 5 x 10^17 = 250,000 >> 10
Moral (DS道义)
When looking for a property (e.g., “two people stayed at the same hotel twice”), make sure that the property does not allow so many possibilities that random data will surely produce facts “of interest.”
简单的说,就是需要发现的规则不要受到太多因素的影响。
MapReduce
Work flow of MapReduce
- Read inputs as a set of key-value-pairs
- Map transforms input kv-pairs into a new set of k’v’-pairs
- Sorts & Shuffles the k’v’-pairs to output nodes
- All k’v’-pairs with a given k’ are sent to the same reduce
- Reduce processes all k’v’-pairs grouped by key into new k’’v’’-pairs
- Write the resulting pairs to files
example: documents word count
Problem: Counting the number of occurrences for each word in a collection of documents
Input: A repository of documents, and each document is an element
Map function:
The Map task reads a document and breaks it into its sequence of words w1, w2, . . . , wn.
It then emits a sequence of key-value pairs where the value is always 1. (w1, 1), (w2, 1), . . . ,(wn, 1)
When the Reduce function is associative and commutative, we can push some of what the reducers do to the Map tasks:
An option, is to combine m key-value pairs (w, 1) into a single pair (w, m).
Reduce function:
The output of a reducer consists of the word and the sum (w, m), where w is a word that appears at least once among.
Collects all values and aggregates by key.
1 | |
MapReduce Environment
Partitioningthe input dataSchedulingthe program’s execution across a set of machines- Performing the
group by keystep : In practice this is the bottleneck - Handling machine
failures - Managing required inter-machine:
Communication
Dataflow
- Input and final output are stored on a distributed file system (HDFS): Scheduler tries to schedule map tasks “close” to physical storage location of input data
- Intermediate results are stored on local FS of Map and Reduce workers
- Output is often input to another MapReduce task.
Grouping by Key
After all Map tasks have all completed successfully:Key-value pairs are grouped by key(Values associated with each key are formed into a list of values)
Grouping is performed by the system, regardless of what the Map and Reduce tasks do
The master controller typically applies a hash function to keys and produces a bucket number from 0 to r-1
Each key that is output by a Map task is hashed and its key-value pair is put in one of r local files
Each file is sent to one of the Reduce tasks.
技巧
Why perform task in the Map task rather than the Reduce task? Reduce communication: send less data over network; Perform logic in the Map where possible without introducing errors.
Reference book
Mining of Massive Datasets: http://infolab.stanford.edu/~ullman/mmds/book.pdf
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!