知识图谱实体链接
NLP中的实体任务
- NER (Recognition): detecting the phrase that is the name of an entity 实体发现
- NEC (Classification): assigning an entity type to the phrase 实体类型分类
- NEL (Linking): establishing the identity of the entity in a given reference
database (Wikipedia, DBpedia, YAGO) 实体链接 - Coreference: any phrase that makes reference to an entity instance, including
pronouns, noun phrases, abbreviations, acronyms, etc… 实体指代
Named Entity Linking (NEL)
Problem statement:
Potentially ambiguous entity mention (“Paris”) needs to be linked to a canonical identifier/instance (http://dbpedia.org/resource/Paris) that fits the intended referent in the context of the text
entity linking (text -> KG)
Named Entity Recognition and Disambiguation (NERD)
假设: the mentions are already recognized in text
Combine recognition and disambiguation/linking -> NERD
NERC + NED = NERD
Knowledge bases
A catalog of things, usually entities. Each one has:
one or more names;
other attributes;
Connections to other entities
Textual description;
Knowledge bases are also connected to each other
Example:
Structured knowledge bases: DBpedia & Wikidata
Unstructured knowledge bases: Wikipedia
实体链接的好处
Benefits of connecting text and knowledge bases:
Automatic knowledge base construction (AKBC) / Knowledge base completion (KBC)帮助KB的完善
实体链接的挑战
- name ambiguity: Entities with the same name
- name variation: Different names for the same entity
- Missing (NIL) entities
实体链接框架
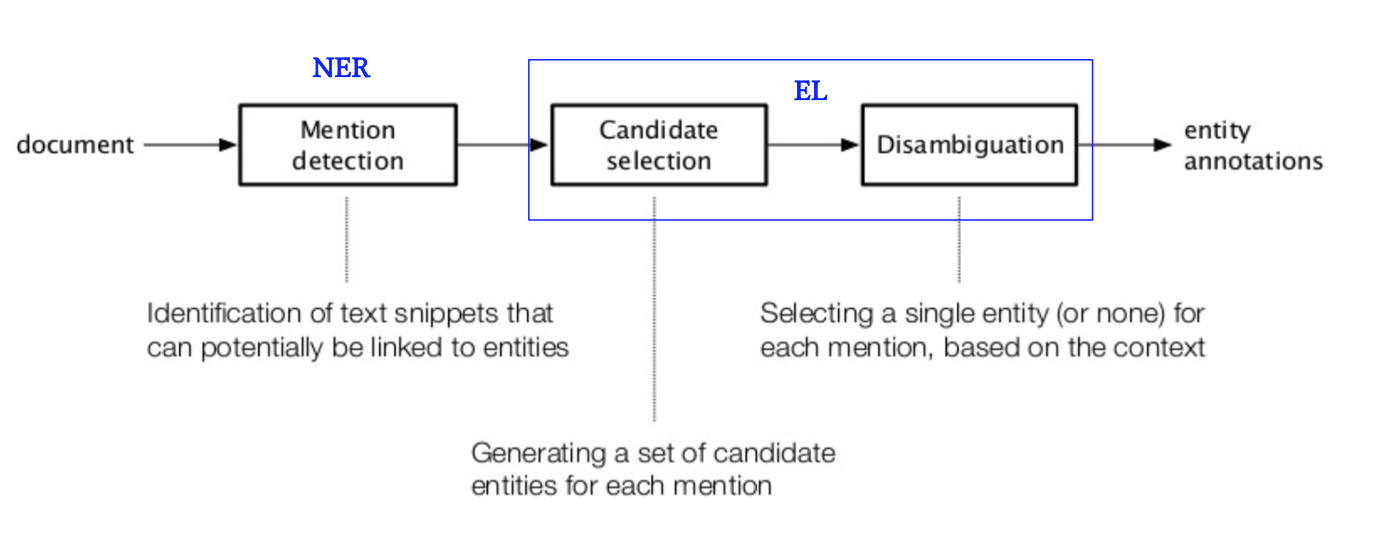
Mention Detection (NER)
在文档中识别出潜在的实体
Candidate generation/selection
Balance between generating too many candidates (too much ‘noise’) and generating too little candidates (missing the correct one)
Trade-off between precision and recall -> an art by itself!
In practice, something like 30 candidates per mention is usually enough
如何选择top30?
commonness: for a given mention, how relatively often it refers to some instance in Wikipedia.
Also, observe dominance within a form and topical bias
Disambiguation
Goal: decide which of the candidates (or none) is the correct referent.
方法:
Word-based methods: DBpedia Spotlight
Compute cosine similarity between the text paragraph with an entity mention and Wikipedia descriptions of each candidateGraph-based methods: AIDA and AGDISTIS
Construct a subgraph that contains all entity candidates with some facts from a KB, then find the best connected candidates per mention.
实体链接的评估
- Assign a true positive (TP), false positive (FP), and/or false negative (FN) per mention occurrence
- Count the TPs, FPs, and FNs across all mentions
- Compute precision, recall, and F1-scores once on top of these
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!