知识图谱数据提取
NLP是数据提取中不可缺少的元素
NLP 基础
什么是NLP?
Program computers to process and analyze large amounts of natural language data.
Unstructured、Ambiguous、Lots and lots of data
=> Structured、Precise、Actionable Specific to the task data
By Information Extraction
什么是信息提取?
Information extraction is the process of extracting information from unstructured textual sources to enable finding entities as well as classifying and storing them. (https://www.ontotext.com/knowledgehub/fundamentals/information-extraction/)
Information Extraction 总览
信息提取的三个阶段:
- 从sentence中提取
- Part of speech tagging 词性标注
- Dependency Parsing 依存分析
- Named entity recognition 命名实体识别
- 从document中提取
- Coreference Resolution 指代消解
- 多个document提取
- Entity resolution 实体解析
- Entity linking 实体链接
- Relation extraction 关系提取
从sentence说起
信息从句子中提取之前么,首先需要进行Tokenization & Sentence Splitting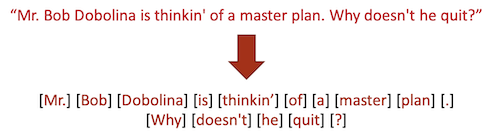
对于Knowledge Graph造成的影响:
- Strictly constrains other NLP tasks
- Parts of Speech
- Dependency Parsing
- Directly effects KG nodes/edges
- Mention boundaries
- Relations within sentences
词性标注(Tagging Parts of Speech)

Context matters.
Label whole sentence together.
Using Conditional Random Fields, CNN, LSTM to do such task.
对于Knowledge Graph造成的影响:
- Entities appear as nouns
- Verbs are very useful
- For identifying relations
- For identifying entity types
- Important for downstream NLP (NER, Dependency Parsing…)
实体识别(Detecting Named Entities)

Context matters.
Label whole sentence together
对于Knowledge Graph造成的影响:
- Mentions describes the nodes
- Types of entities are incredibly important(Often restrict relations).
依存分析(Dependency Parsing)

通过使用模型来对预测的依存关系进行打分来预测。
对于Knowledge Graph造成的影响:
- Incredibly useful for relations!
- Incredibly useful for attributes!
- Paths are used as surface relations
Surface relation: 仅仅根据句子的结构而不借助语义分析来判定关系模式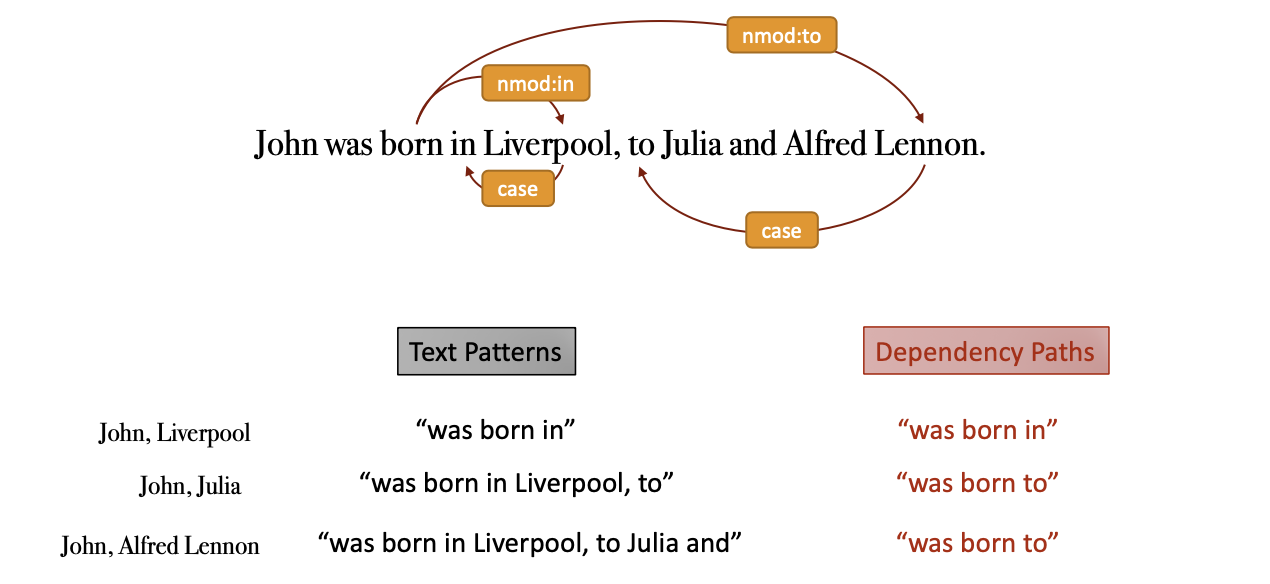
一个Document中的多个sentence
文档间指代(Within-document Coreference)

实现方式:
Model: score pairwise links, exmaple: dep path, similarity, representative mention …
Prediction: Search over clusterings, example: greedy (left to right), ILP,
belief propagation, MCMC …
对于Knowledge Graph造成的影响:
More context for each entity!
Many relations occur on pronouns.
Coref can be used for types.
Difficult, so often ignored.
文档间、不同源间的信息提取
=> Information Extraction
- Entity resolution 实体解析
- Entity linking 实体链接
- Relation extraction 关系提取
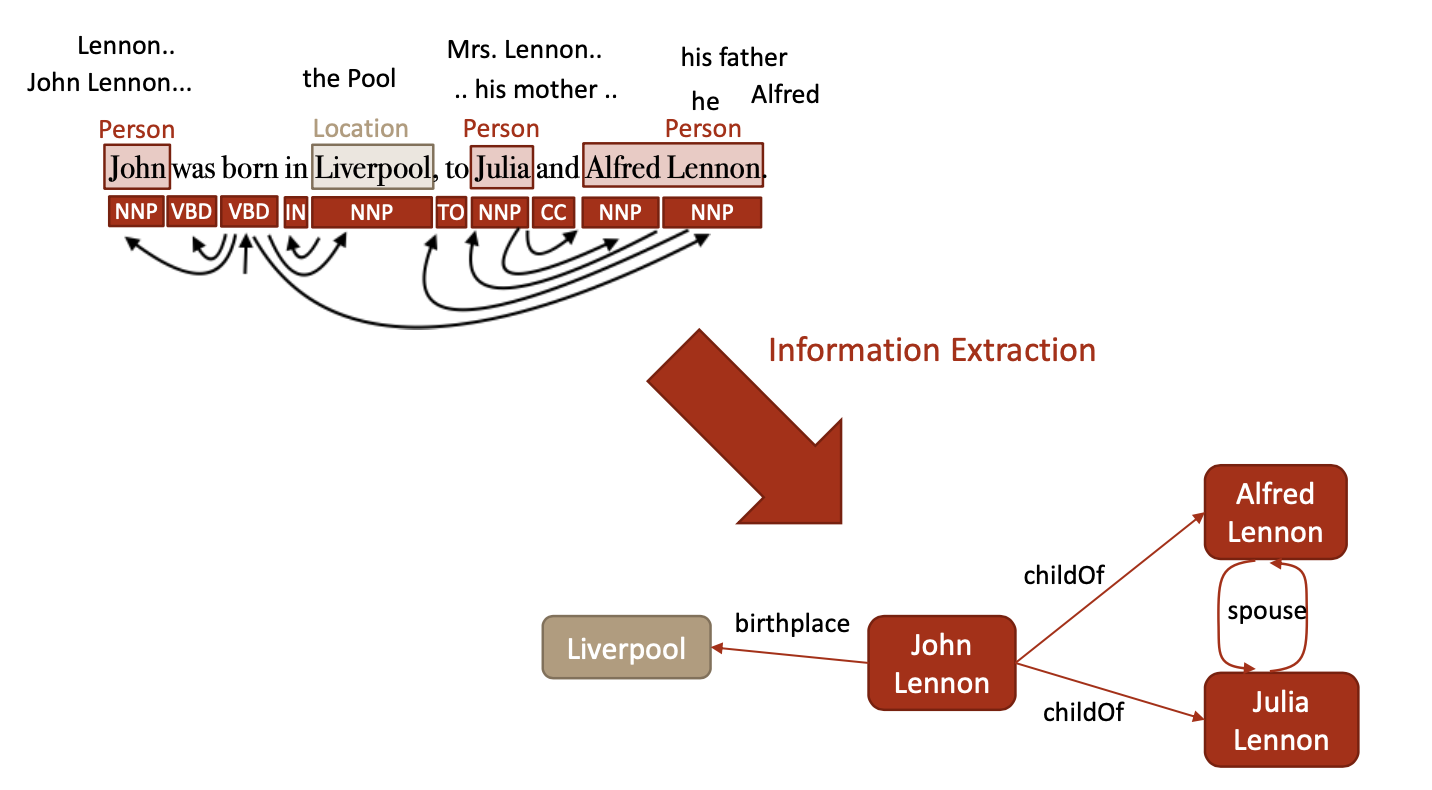
Information Extraction 细节
表面模式 Surface Patterns
Combine tokens, dependency paths, and entity types to define rules.
简单的说,就是根据句子、文档的语法结构来判断分析出实体间的关系模式,而忽略了句子的语义信息。
Rule-Based Extraction
通过人为的规定某些语法模式,根据句子的结构来信息提取。
来源:
Manually specified, Learned from Data
效果:
High precision: when it fires, it’s correct Easy to explain predictions. Easy to fix mistakes.
Poor recall: Do not generalize! Only work when the rules fire
Supervised Extraction
通过使用机器学习算法来进行信息的提取
Machine Learning: hopefully, generalizes the labels in the right way
Use all of NLP as features: words, POS, NER, dependencies, embeddings
缺陷:
Requires a lot of labeled data is needed, which is expensive & time consuming.
Requires a lot of feature engineering!
Entity Resolution & Linking
命名实体存在的问题:
- Different Entities with Same Name
- Different Names for same Entities
一般步骤:
Candidate Generation => Entity Types => Coreference => Coherence
Information Extraction 三个子问题及解决方式
3*3 = 9

Defining Domain
Manual
Highly semantic ontology;
Leads to high precision extraction;
Expensive to create;
Requires domain experts;
Semi-automatic
Subset of types are manually defined;
SSL methods discover new types from unlabeled data;
Easier to derive types using existing resources;
Relations are discovered from the corpus;
Leads to moderate precision extractions;
Partially semantic ontology;
Example:
Assumption:
Types and type hierarchy is manually defined (E.g. River, City, Food, Chemical, Disease, Bacteria);
Relations are automatically discovered using clustering methods
Automatic
Any noun phrase is a candidate entity
Any verb phrase is a candidate relation
Cheapest way to induce types/ relations from corpus;
Little expert annotations needed;
Limited semantics;
Leads to noisy extractions;
Learning extractors
Manual
Human defined high-precision extraction patterns for each relation
Semi-supervised
Bootstrapping
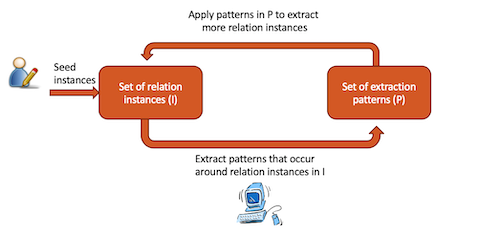
简单的说就是,人为给一些seed instances给机器,让机器去提取符合这些instance的pattern,然后根据提取到的pattern去提取符合的instance,重复操作,获取越来越多的instance和pattern.
缺陷:Semantic Drift, 语义漂移
解决方式: topk, interactive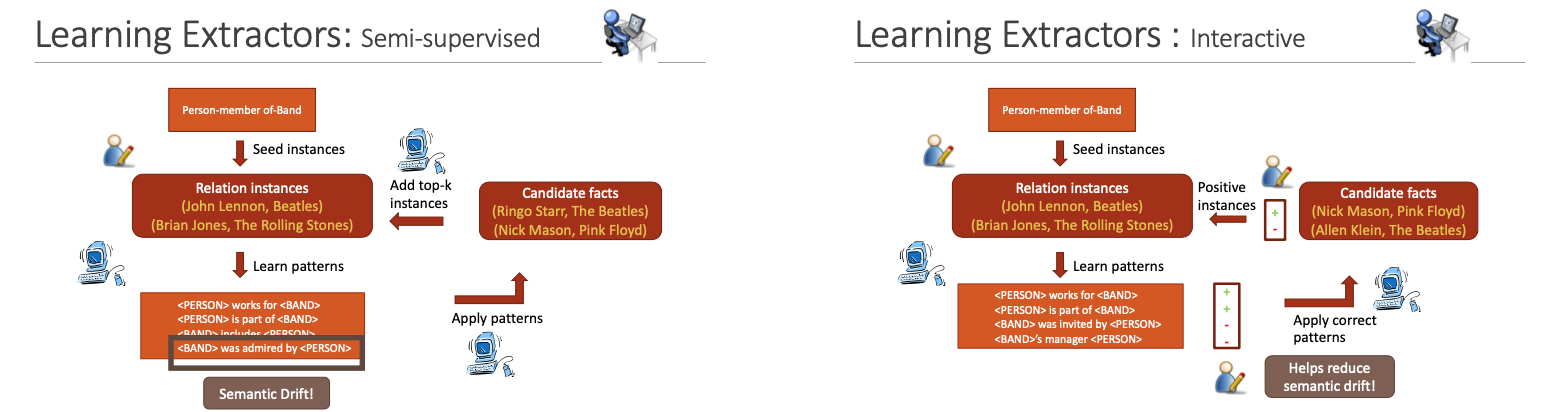
Unsupervised
Identify candidate relations: 为每个动词找到最长的单词序列
Identify arguments for each relation: 对于每个关系,找其左侧和右侧找到最接近的名词短语
Scoring candidate facts
Manual
Human defined scoring function or Scoring function learnt using supervised ML with large amount of training data
Semi-supervised
Small amount of training data is available. Scoring refined over multiple iterations
Using both labeled and unlabeled data
Unsupervised
Confidence(extraction pattern) ∝ (#unique instances it could extract)
Score(candidate fact) ∝ (#distinct extraction patterns that support it)
Information Extraction 技术类别
Narrow domain patterns
Defining domain: Manual
Learning extractors: Manual
Scoring candidate facts: Manual
Ontology based extraction
Defining domain: Manual
Learning extractors: Semi-supervised
Scoring candidate facts: Unsupervised
Interactive extraction
Defining domain: Manual
Learning extractors: Semi-supervised
Scoring candidate facts: Semi-supervised
Open domain IE
Defining domain: Unsupervised
Learning extractors: Unsupervised
Scoring candidate facts: Semi-supervised
Hybrid approach (Adding structure to OpenIE KB)
Defining domain: Semi-supervised => Distant supervision to add structure
Learning extractors: Unsupervised
Scoring candidate facts: Semi-supervised
Knowledge fusion
融合多种Learning extractors来提高提取准确度
Knowledge fusion schemes:
- Voting (AND vs OR of extractors)
- Co-training (multiple extraction methods)
- Multi-view learning (multiple data sources)
- Classification
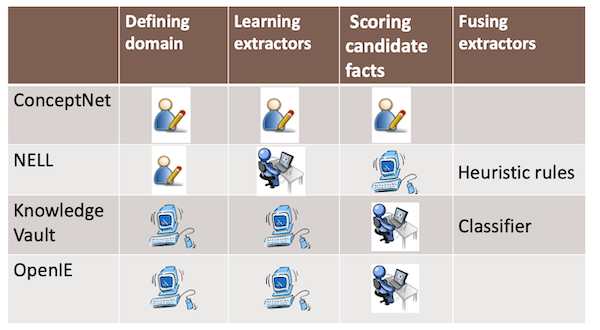
IE systems in practice
- Conceptnet
- NELL (Never Ending Language Learning )
- Knowledge vault
- Open IE
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!