知识图谱字符串匹配
字符串匹配问题
Problem Statement:
Given X and Y sets of strings, Find pairs (x, y) such that both x and y refer to the same real world entity.
Then use precision(fraction of pairs found that are correct) and recall(fraction of pairs found) to evaluate algorithms
Why can’t match perfectly
Typos “Joh” vs. “Jhon”
OCR errors “J0hn” vs “John”
Formatting conventions ”03/17” vs “March 17”
Abbreviations “J. S. Sargent” vs “John Singer Sargent”
Nick name ”John” vs “Jock”
Word order “Sargent, John S.” vs “John S. Sargent”
因此,转而计算字符串的相似度
Similiarity Measure
Similarity(x, y) in [0, 1] is better than distance(x, y) in [0, ∞)
Types of Similarity Metrics:
- Sequence based
- Set based
- Hybrid
- Phonetic
Sequence Based Metrics
Edit Distance/Levenshtein Distance
Online calculator: http://planetcalc.com/1721/
lev(x, y) is the minimum cost to transform x to y(insert,delete,substitute)
原理: 动态规划 d(i,j)
case1: xi = yj => d(i,j) = d(i-1,j-1)
case2: xi != yj => d(i,j) = min( d(i-1,j) + 1 , d(i,j-1) + 1 , d(i-1,j-1) + 1)
缺陷:
Too high a cost for deleting a sequence of characters, so it is not suitable for abbreviation cases (example: lev(John Singer Sargent,John S. Sargent ) = 5, lev(John Singer Sargent,John Klinger Sargent ) = 5 )
Needleman-Wunch Measure
Generalization of levenstein(x, y), 为了解决lev带来的缩写问题的一种新的度量方式
得到的结果是两个string相似的评分,而不是距离

缺陷:
Longer gaps are penalized more, bad for names (example:nw(John Singer Sargent,John S. Sargent) = 25, nw(John Stanislaus Sargent,John S. Sargent)
Affine Gap Measure
Generalization of needleman-wunch(x, y),为了解决Needleman-Wunch带来的长gap问题
Intuition: two small gaps are worse than one large one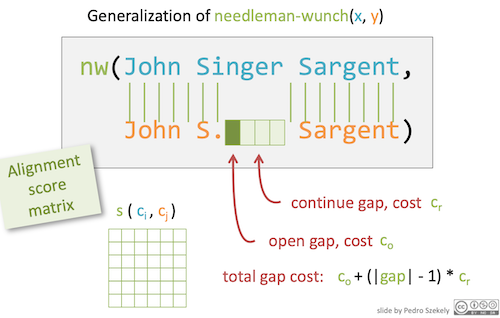
Smith-Waterman
可以说是Needleman-Wunch的local版本
Needleman-Wunch: Fully align sequences, opening gaps as needed,也就是说两边空格都被考虑进去了的
Jaro Similarity Measure
Get points for having characters in common
• but only if they are “close by”
Get points for common characters in the same order
• lose points for transpositions
???
Jaro-Winkler Measure
????
Set-Based Metrics
Generate set of tokens from the strings and then measure similarity between the sets of tokens
Jaccard Measure
TF-IDF Measure
Hybrid Similarity Measures
Do the set-based thing but use a similiarity metric for each element of the set
Generalized Jaccard Measure
The Soft TF/IDF Measure
Monge-Elkan Measure
Phonetic Similarity
Soundex
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!