知识图谱Blocking&关系型实体解析
实体解析回顾
Deduplication: Merging Ambiguous Entities (KG->KG)
Record Linkage: Combining KGs (KG1->KG2)
Entity Mapping/Linking: Integrating New Candidates (text -> KG)
Blocking
简单匹配的问题: Comparing each entity with all other entities is too computationally demanding – O(N2)
解决: Partition entities into ”blocks” – O(N) blocks
Make only within block comparisons [so if largest block is log N in size – O(N log N2)]
Problem statment:
Input: Set of records R Output: Set of blocks/canopies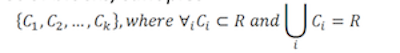
Variants:
Disjoint Blocking: Each mention appears in one block. (=Set Partition)
Non-disjoint Blocking: Mentions can appear in more than one block.
Blocking 场景
Ideal scenario
Worst scenario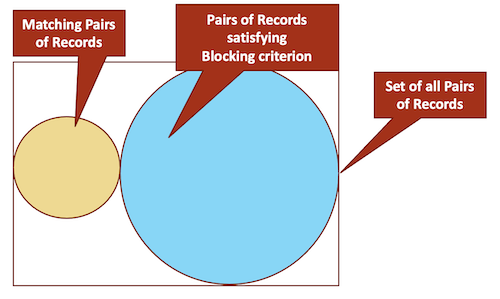
Practical Scenario
评估指标
Efficiency = num of pairs compared / total number of pairs in RxR
Recall = num of true matches compared / num of true matches in RxR
Precision = um of true matches compared / num of matches compared
Max Canopy Size: max|Ci|
Blocking 方式
- Feature-based blocking keys
- Clustering or sorting
- Hashing
Feature-based blocking
思想:
Pick a key: an attribute or feature of each entity
Put all entities with that key in the same block
Perform entity resolution within each block
Key的选择考量:
Learn the keys, or use expert knowledge/heuristics
Schema awareness
Key type
Redundancy
Key选择扩展:
Frequency limits
Adaptive keys based on frequency
Learning keys based on data
Sort or cluster-based blocking
思想:
Pick an attribute
Sort all entities based on that attribute
Use a sliding window of |K| entities and compare all pairs.
Canopy Clustering [McCallum et al KDD’00]
Input:
- Mentions M (a set of entities that are needed to be cluster), x is an random chosen entity from M.
- d(x,y), a distance metric
- Two thresholds T1 and T2, where T1 > T2
Algorithm:
- 从M中选择一个随机的x
- 为x生成一个block,其中的点满足d(x,y) < T1
- 为x中这个block,删除符合d(x,y)<T2的点 (it means that we are finishing assigning cluster labels to y)
- 返回第一步 (repeat until all entities in M are assigned to at least one cluster)
Hash-based blocking
思想:
Each block Ci is associated with a hash key hi.
Mention x is hashed to Ci if hash(x) = hi.
Within a block, all pairs are compared.
Each hash function results in disjoint blocks.
minhash
…
Collective Relational Entity Resolution
策略:
Using PSL for collective KG ER
Encode ER dependencies in a set of rules;
Use soft-logic values to capture similarities;
Use logic to capture the constraints;
Local vs. Collective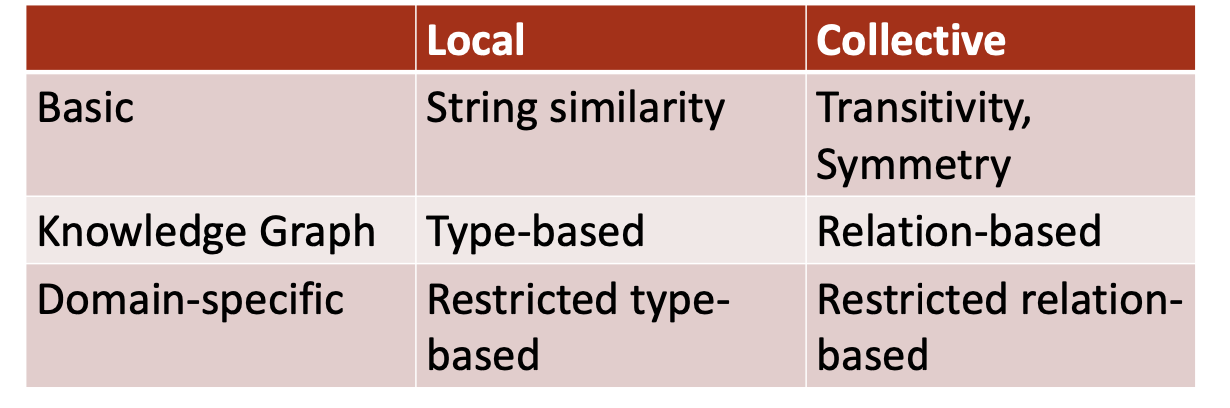
Basic
¬SAME(E1,E2)
CANDSAME(E1,E2) => SAME(E1,E2)
CANDSAME(E1,E2) ∧ SIM(E1,E2) => SAME(E1,E2)
Collective
Symmetry: If M1 matches with M2, then M2 must match with M1
Transitivity: If M1 and M2 match, M2 and M3 match, then M1 and M3 match
Sparsity: If M1 matches with M2, then M1 cannot match with M3
example:
SAME(E1,E2) => SAME(E2,E1)
CANDSAME(A,B) ∧ CANDSAME(B,C) ∧ CANDSAME(A,C) ∧ SAME(A,B) ∧ SAME(B,C) => SAME(A,C)
CANDSAME(A,B) ∧ CANDSAME(B,C) ∧ SAME(A,B) => ¬SAME(A,C)
New entity rules
- Linking to new entities CANDSAME(E1,E2) ∧ NEWENTITY(E1) => SAME(E1,E2)
- Avoiding new Entities SAME(E1,E2) ∧ CANDSAME(E1,E3) ∧ NEWENTITY(E3) => ¬SAME(E1,E3)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!