知识图谱信息提取-Snorkel
Dark Data Extraction
Structured Data(4%): Data easy to process by machines
Dark Data(96%): Valuable & hard to process. (占据的web信息的绝大部分)
example: Scientific articles & government reports,Medical Images
DDE: Dark Data(Text, Tables, Images, Diagrams, etc) => Structured Data (Enables analyses, interfaces etc.)
DDE 传统流程
1.Candidate Extraction => 2.Training Set => 3.Feature Extraction => 4.Learning & Inference
Example: Chemical-Disease Relation Extraction from Text
方式1: Human defines candidate entity mentions to populate a relational schema with relation mentions (费事费力,需要domain expertis)
方式2: Relation Extraction with Machine Learning (Feature engineering is the bottleneck,however this bottleneck is solved by deep learning) 解决3,但是2没被解决
Training data is THE ML dev bottleneck today.
DDE挑战
Dark data extraction systems still take months or years to build using state-of-the-art machine learning (ML) systems
时间太久,成本太高。
Training Data Creation: $$$, Slow, Static 成本高,耗时长,灵活性差
- Expensive & Slow: Especially when domain expertise needed
- Static: Real-world problems change but hand-labeled training data does not.
Snorkel
Motiviton: Can we use noisier training data and still train high-performance models?
Snorkel: A System for Rapidly Generating Training Data with Weak Supervision
简单的说,这是一个生成训练集的框架。
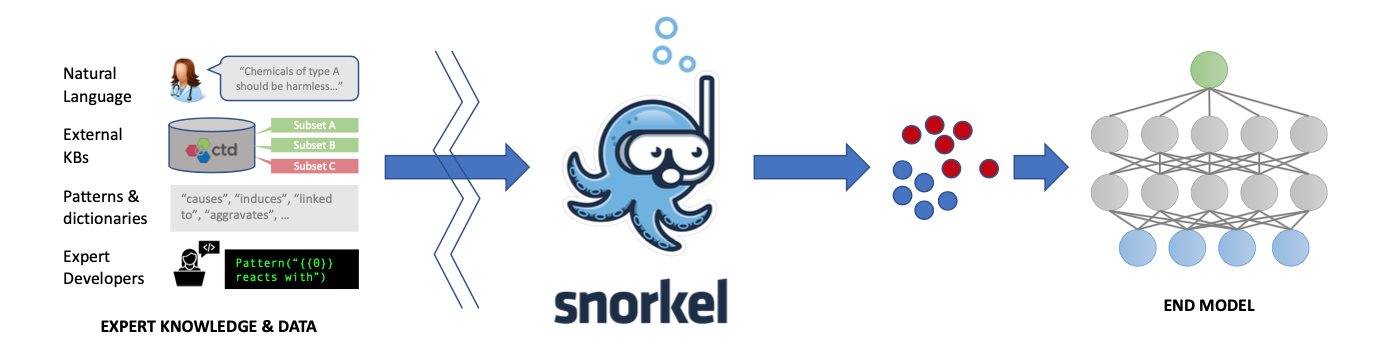
Snorkel Pipeline 概括
- Users write labeling functions to generate noisy labels
- Snorkel models and combine these labels
- We use the resulting probabilistic training labels to train a model
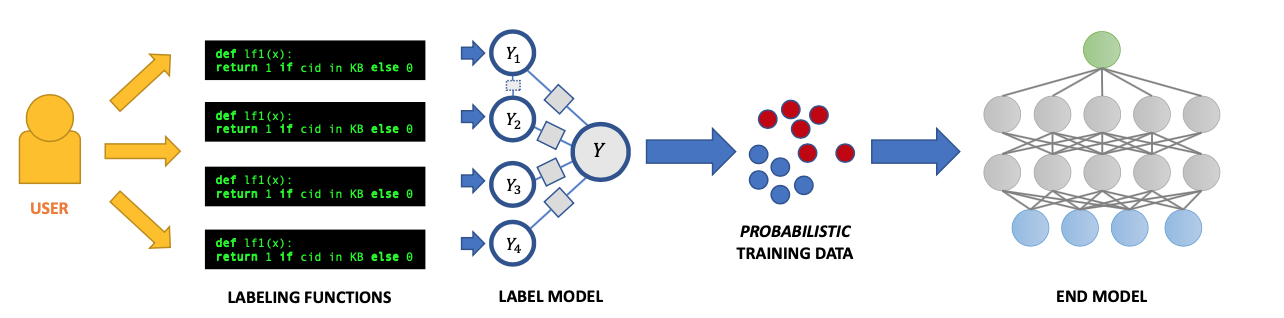
Labeling Functions
Users give Snorkel labeling functions that label data points
简答的说,这个Labeling function的起到的作用和human expertise类似,用于规定一些规则来让snorkel后续过程中发现text里与其匹配的模式来对提取的信息信息标注。
因此,用户可以书写尽可能多的Labeling Functions来提高准确性,并且Labeling Functions之间可以有冲突,因为后续用到的是概率来确定结果。
Model, Combine, Iterate
Snorkel models and combine these labels
这里snorkl根据用户书写的Labeling functions进行建模,并迭代运行模型,得到一个probabilistic training labels
Train End Model
Use the resulting probabilistic training labels to train a model
Snorkel challenge - Step2:
How do we model and combine LFs? How to best reweight and combine the noisy supervision signal?
解决方式: A Generative Model of the Training Data Labeling Process
使用生成式模型反映各个LF得到的标注结果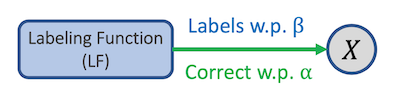
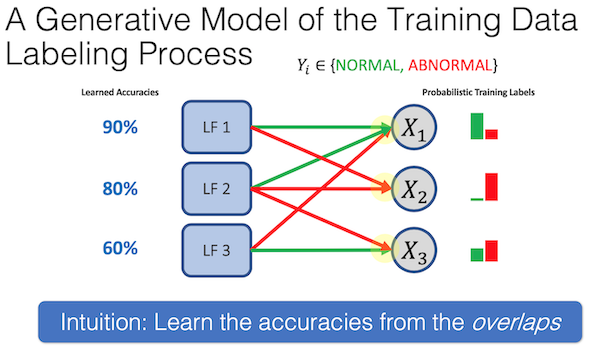
从中也可以发现,LF可以存在冲突,并且对他存在相关联的LF建模分析也能够提高精度。( We can learn dependency structure using statistical and/or static analysis techniques [ICML ’17, NIPS ‘17])
Snorkel Pipeline 细节
Designing Labeling Functions (LFs)
Write heuristics to noisily label data! 区别于人工手动标记,这里snorkel写label function的目的是为了后续的Programmatically generate training data
如何设计Labeling function:
Human annotators leverage real-world knowledge, context, and common-sense heuristics to make labeling decisions
Labeling function 结果:
{-1, 0, 1} => {Negative, Abstain, Positive}
流程:
text中提取candidates,candidates中包含true和false的instances,使用设计的Labeling function来判断candidate为true或false
目标:
Apply labeling functions to all candidates to predict both positive and negative labels
Tip:
Labeling functions can be noisy,毕竟无法涵盖所有范围,所有语境。
设计策略:
Pattern-based Labeling Functions
Common sense patterns or keywords
String matching via regular expressions and other heuristicsDistant Supervision Labeling Functions
Use an existing database of known facts to generate noisy labels
LF评价指标:
Accuracy: percentage of candidates a labeling function labels correctly
Coverage: percentage of all candidates that are labeled by >= 1 LFs
Conflict: percentage of candidates with >1 labels that disagree
LF选择标准:
We want high-coverage, high-accuracy LFs
LFs need to label with probability better than random chance
Conflict is actually good — it allows our algorithm to learn information about the LF
Build Generative Model: Unifying Supervision
Simple Baseline: Majority Vote
Automatically Learning LF Accuracies
LF Dependency Learning
Build Discriminative Model: “Compiling” Rules into Features
Training with Probabilistic Labels
The Death of Manual Feature Engineering
Why Do We Need the Discriminative Model?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!